储能科学与技术 ›› 2025, Vol. 14 ›› Issue (5): 1982-1990.doi: 10.19799/j.cnki.2095-4239.2024.1130
萨仁高娃1( ), 邬超慧1, 倪泽龙2, 张悦1, 姜新建2(), 田建宇2
), 邬超慧1, 倪泽龙2, 张悦1, 姜新建2(), 田建宇2
收稿日期:2024-11-27
修回日期:2024-12-02
出版日期:2025-05-28
发布日期:2025-05-21
通讯作者:
姜新建
E-mail:1764861384@qq.com;jiangxj@mail.tsinghua.edu.cn
作者简介:萨仁高娃(1976—),女,学士,高级工程师,从事电力系统、机电一体化研究,E-mail:1764861384@qq.com;
基金资助:
Rengaowa SA1(), Chaohui WU1, Zelong NI2, Yue ZHANG1, Xinjian JIANG2(), Jianyu TIAN2
Received:2024-11-27
Revised:2024-12-02
Online:2025-05-28
Published:2025-05-21
Contact:
Xinjian JIANG
E-mail:1764861384@qq.com;jiangxj@mail.tsinghua.edu.cn
摘要:
本工作对基于电磁耦合器的惯量飞轮系统进行了研究,首先介绍了惯量飞轮系统的拓扑结构、原理,并说明了采用电磁耦合器的优势,然后对惯量飞轮系统进行数学建模。由于传统的定参数PID控制方式在系统有功指令突变的时候,输出功率会发生较大的波动,因此本工作提出了一种基于强化学习的变参数PID有功控制策略。在该控制策略中,PID参数是通过无模型参考的强化学习算法训练的神经网络RL Agent得到的,神经网络的输入量是有功功率的偏差、有功功率的微分、转速、转速的微分,输出量是P、I、D三个参数,当系统状态发生变化的时候,PID参数也会随之改变。为了验证该控制策略的可行性与控制性能的优势,在MATLAB/Simulink仿真平台上对该控制策略进行了与传统的定参数PID控制方式的对比验证,仿真结果表明,变参数PID控制策略中的P、I参数在系统收到有功功率调节指令时都有明显的变化,导致输出转矩的参考值发生了改变,从而使得系统功率输出的超调量和波动更小,动态响应性能更好。
中图分类号:
萨仁高娃, 邬超慧, 倪泽龙, 张悦, 姜新建, 田建宇. 基于强化学习的变参数PID的惯量飞轮有功控制策略[J]. 储能科学与技术, 2025, 14(5): 1982-1990.
Rengaowa SA, Chaohui WU, Zelong NI, Yue ZHANG, Xinjian JIANG, Jianyu TIAN. A variable-parameter PID active power control strategy of inertial flywheel based on reinforcement learning[J]. Energy Storage Science and Technology, 2025, 14(5): 1982-1990.
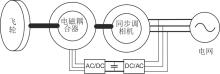
图1
基于电磁耦合器的惯量飞轮系统结构图"
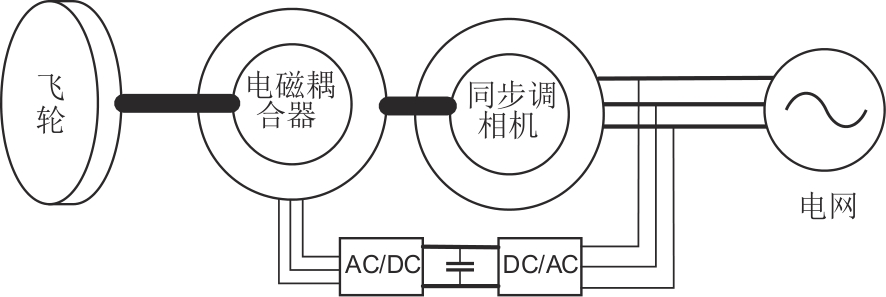
图2
电磁耦合器结构图"

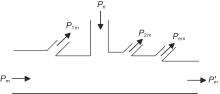
图3
功率流程图"

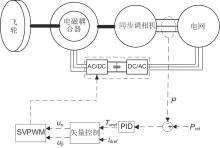
图4
传统PID结合矢量控制策略框图"
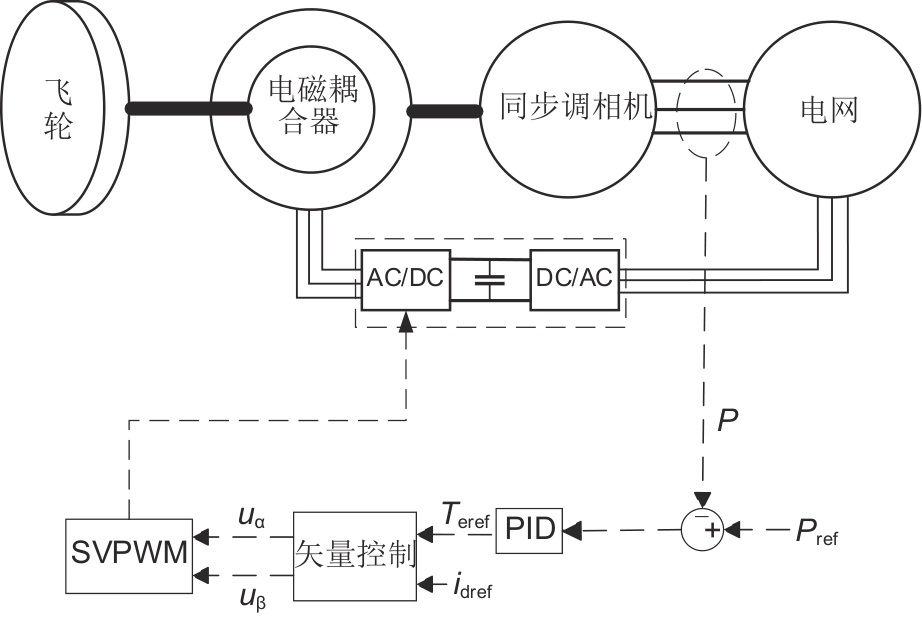
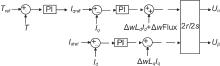
图5
矢量控制策略框图"

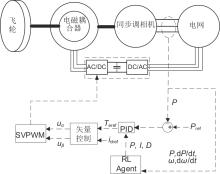
图6
基于强化学习的变参数PID控制策略框图"
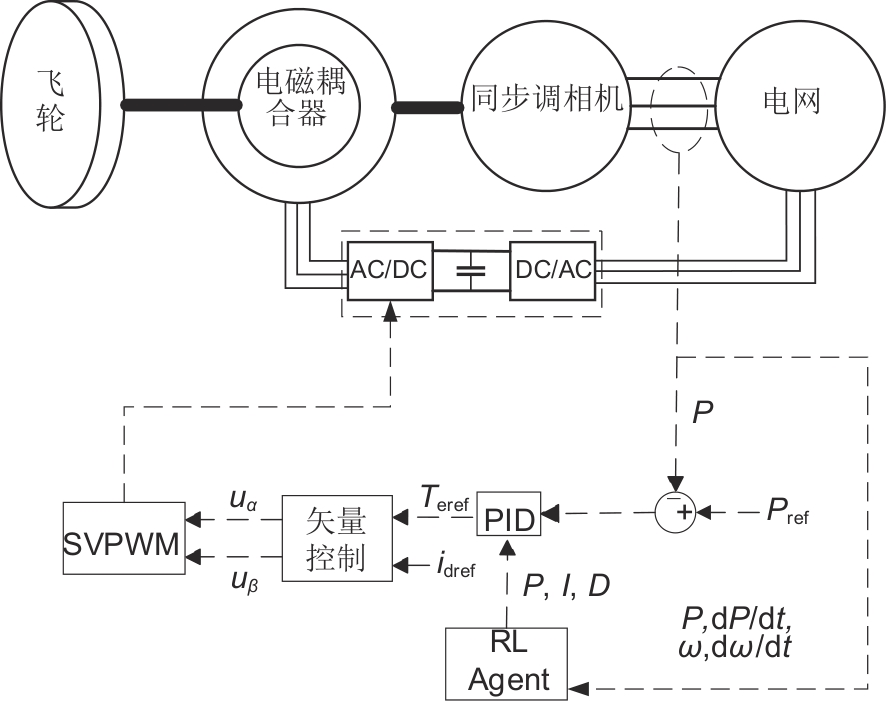

图7
采用强化学习算法训练神经网络的流程图"
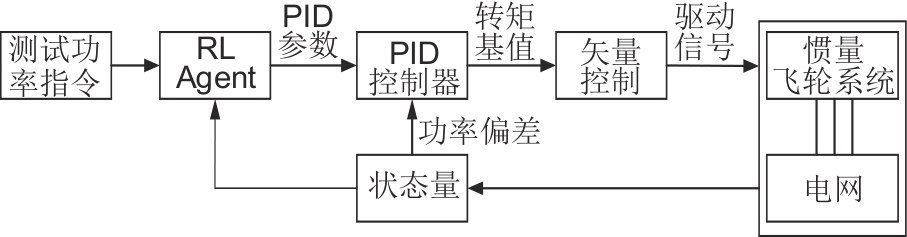
表1
DDPG算法流程"
| DDPG算法流程 |
|---|
初始化: 随机初始化Actor网络和Critic网络的参数; 初始化目标网络; 初始化经验回放池R。 重复迭代次数(episode): 随机初始化过程以进行动作探索。 获得初始状态值 s0。 重复t到T(step): (1)根据当前状态 st 计算当前时间步的动作 at。 (2)执行动作 at,并记录奖励rt 和新的状态 st+1。 (3)存储转换经验( st, at, rt, st+1)在经验池R中。 (4)从经验池R随机采样小批量的转换经验样本( si, ai, ri, si+1)。 (5)最小化损失函数更新Critic网络。 (6)使用梯度算法更新Actor网络。 (7)更新目标网络[ |
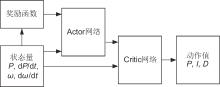
图8
神经网络参数迭代"

表2
电磁耦合器参数"
| 参数 | 取值 |
|---|---|
| 额定电压/V | 690 |
| 额定转速/(r/min) | 300 |
| 极对数 | 10 |
| 相电阻/Ω | 0.086 |
表3
同步调相机参数"
| 参数 | 取值 |
|---|---|
| 额定容量/(MV·A) | 2 |
| 额定电压/kV | 10 |
| 极对数 | 1 |
| 相电阻(p.u.) | 0.02758 |
| 惯性时间常数/s | 0.8 |
表4
惯量飞轮参数"
| 参数 | 取值 |
|---|---|
| 惯量/(kg·m2) | 200 |
| 转速范围/(r/min) | 2700~3000 |
| 储能量/MJ | 1.875 |

图9
飞轮转速波形图"

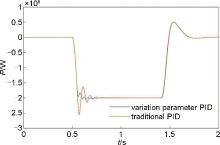
图10
系统功率波形图"
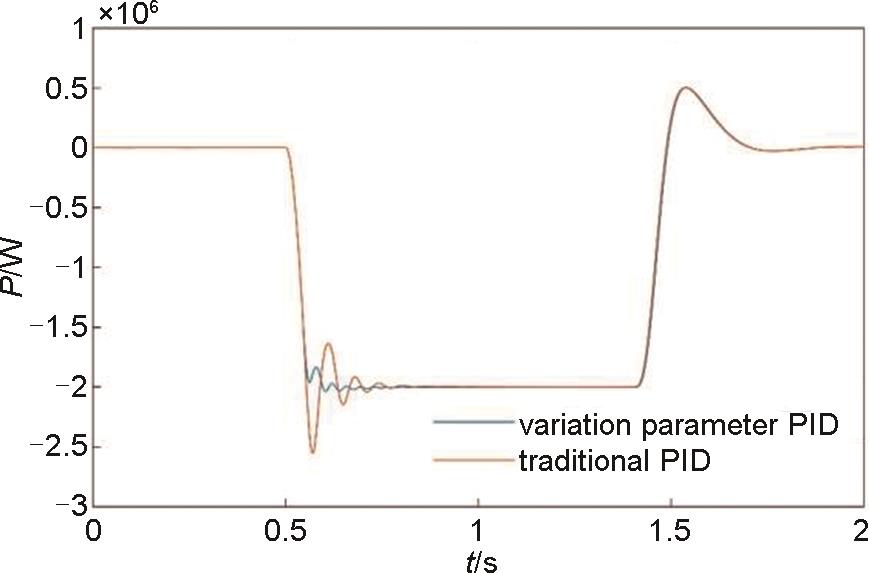
图11
系统功率局部放大图"
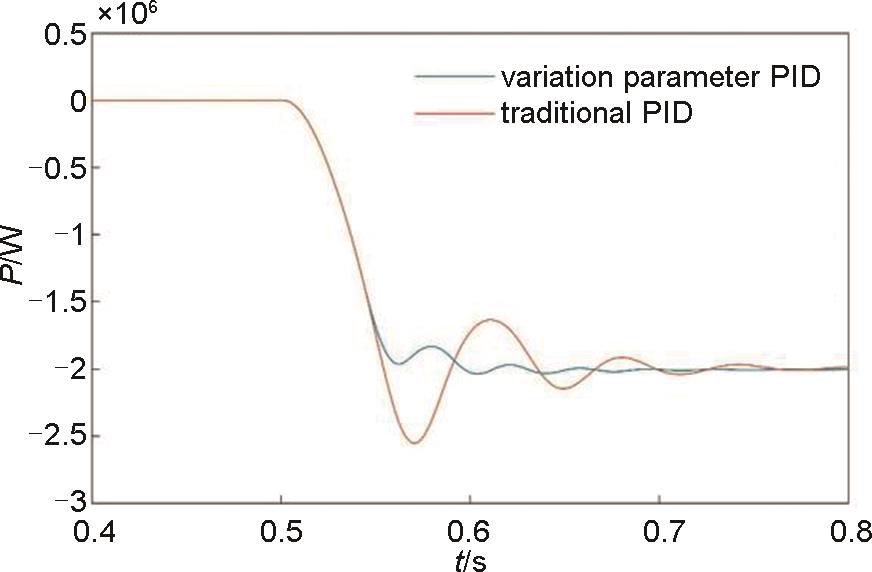
图12
P 参数波形图"
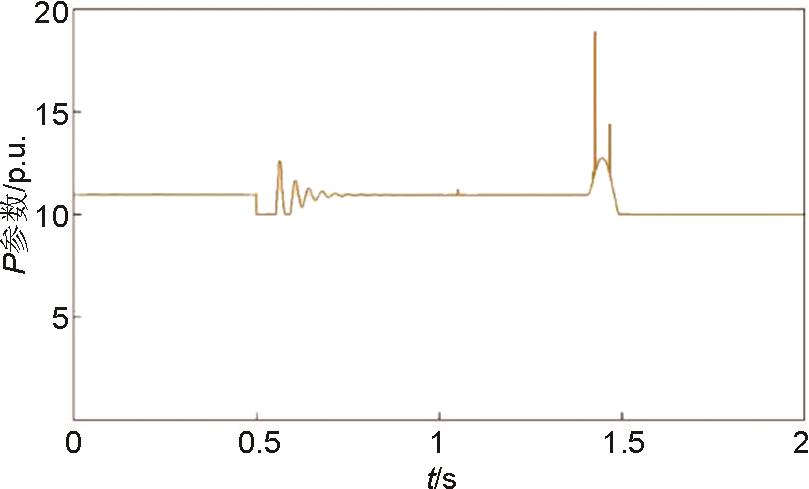
图13
I 参数波形图"
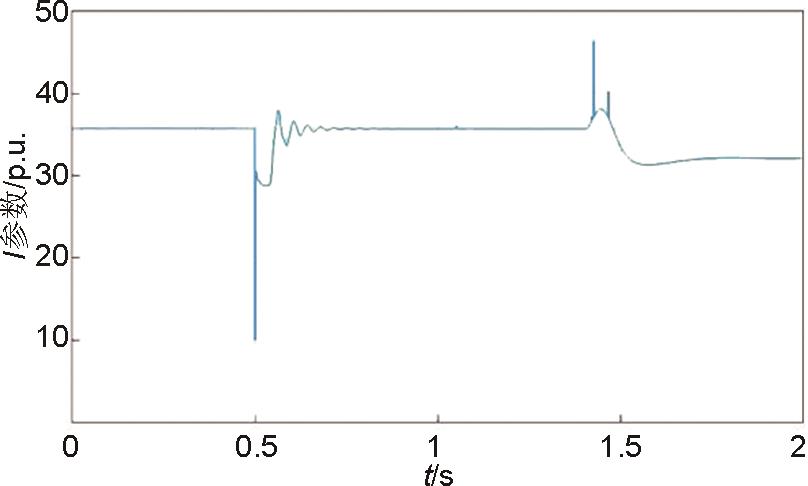
图14
D 参数波形图"
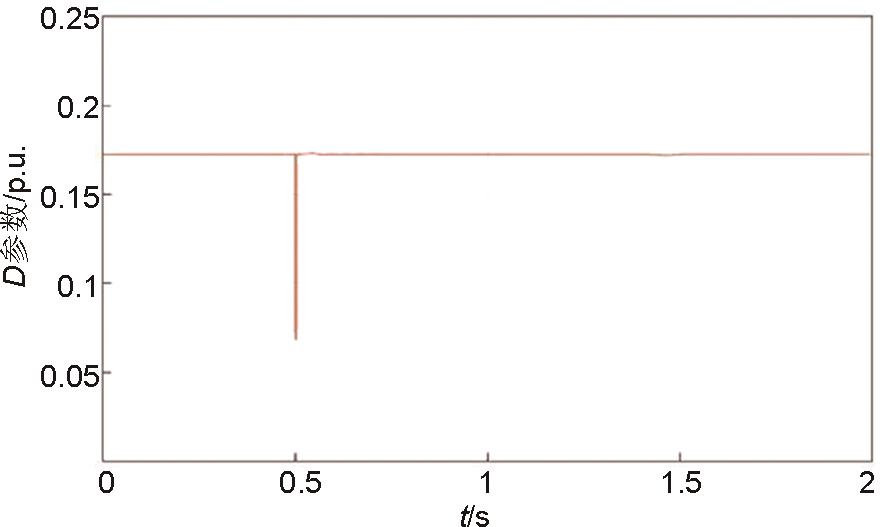
图15
电磁耦合器电磁转矩波形图"
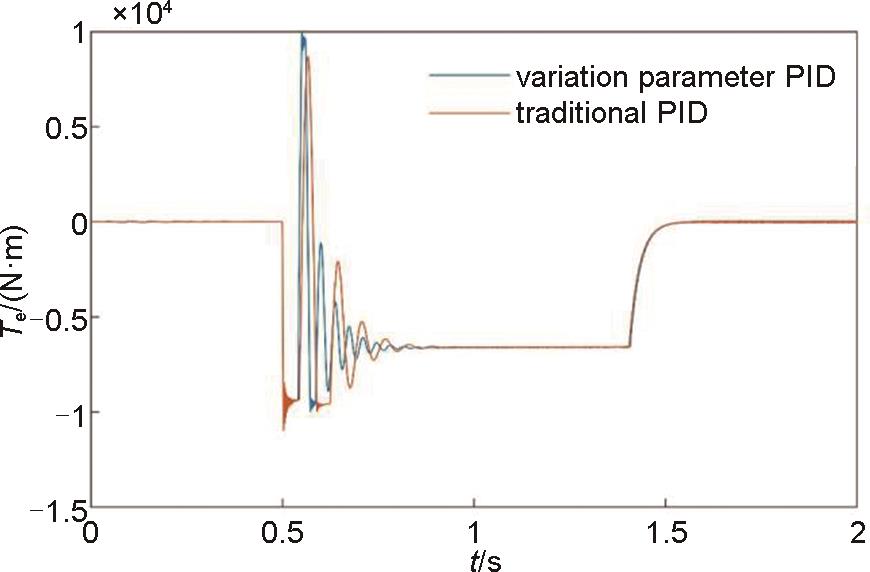
图16
电磁耦合器功率波形图"
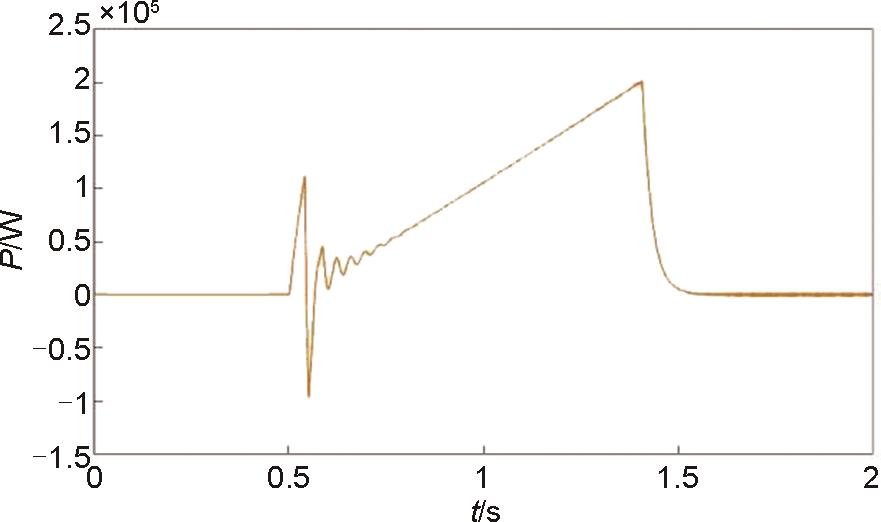
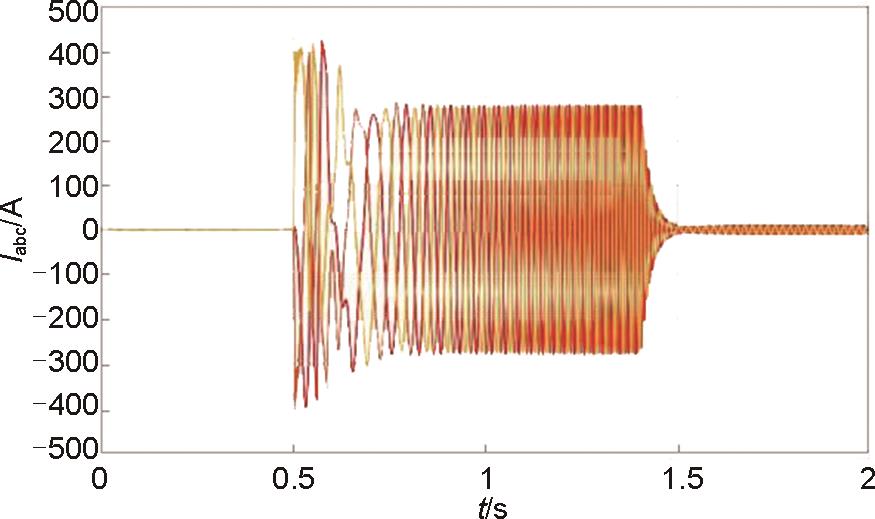
图17
电磁耦合器电流波形图"
| 1 | 张智刚, 康重庆. 碳中和目标下构建新型电力系统的挑战与展望[J]. 中国电机工程学报, 2022, 42(8): 2806-2819. DOI: 10.13334/j.0258-8013.pcsee.220467. |
| ZHANG Z G, KANG C Q. Challenges and prospects for constructing the new-type power system towards a carbon neutrality future[J]. Proceedings of the CSEE, 2022, 42(8): 2806-2819. DOI: 10.13334/j.0258-8013.pcsee.220467. | |
| 2 | 董昱, 孙大雁, 许丹, 等. 新型电力系统电力电量平衡的挑战、应对与展望[J]. 中国电机工程学报, 2025, 45(6): 2039-2057. DOI: 10. 13334/j.0258-8013.pcsee.240656. |
| DONG Y, SUN D Y, XU D, et al. Challenges, response and prospects for power balance in new power systems[J]. Proceedings of the CSEE, 2025, 45(6): 2039-2057. DOI: 10. 13334/j.0258-8013.pcsee.240656. | |
| 3 | 张子扬, 张宁, 杜尔顺, 等. 双高电力系统频率安全问题评述及其应对措施[J]. 中国电机工程学报, 2022, 42(1): 1-25. DOI: 10.13334/j. 0258-8013.pcsee.211425. |
| ZHANG Z Y, ZHANG N, DU E S, et al. Review and countermeasures on frequency security issues of power systems with high shares of renewables and power electronics[J]. Proceedings of the CSEE, 2022, 42(1): 1-25. DOI: 10.13334/j. 0258-8013.pcsee.211425. | |
| 4 | 喻恒凝, 姚良忠, 程帆, 等. 重力储能在新型电力系统中应用: 前景及挑战[J/OL]. 中国电机工程学报, 2024: 1-16. (2024-08-26). https://link.cnki.net/doi/10.13334/j.0258-8013.pcsee.240834. |
| YU H N, YAO L Z, CHENG F, et al. Prospects and challenges of gravity energy storage applications in new type power system[J/OL]. Proceedings of the CSEE, 2024: 1-16. (2024-08-26). https://link.cnki.net/doi/10.13334/j.0258-8013.pcsee.240834. | |
| 5 | 居文平, 王一帆, 赵勇, 等. 新型电力系统长时储能技术综述[J]. 热力发电, 2024, 53(9): 1-9. DOI: 10.19666/j.rlfd.202405093. |
| JU W P, WANG Y F, ZHAO Y, et al. Overview of long-term energy storage technologies in new power systems[J]. Thermal Power Generation, 2024, 53(9): 1-9. DOI: 10.19666/j.rlfd.202405093. | |
| 6 | 代宇涵, 刘春, 周朋, 等. 双碳背景下电力系统储能技术的应用与研究进展[J]. 储能科学与技术, 2024, 13(8): 2772-2774. DOI: 10. 19799/j.cnki.2095-4239.2024.0695. |
| DAI Y H, LIU C, ZHOU P, et al. Application and research progress of energy storage technology in power systems under the dual carbon background[J]. Energy Storage Science and Technology, 2024, 13(8): 2772-2774. DOI: 10.19799/j.cnki.2095-4239.2024.0695. | |
| 7 | 徐帆, 戴兴建, 王又珑, 等. 飞轮储能用永磁电机研究进展[J]. 储能科学与技术, 2024, 13(10): 3423-3441. DOI: 10.19799/j.cnki.2095-4239.2024.0320. |
| XU F, DAI X J, WANG Y L, et al. Research progress on permanent magnet machines for flywheel energy storage[J]. Energy Storage Science and Technology, 2024, 13(10): 3423-3441. DOI: 10.19799/j.cnki.2095-4239.2024.0320. | |
| 8 | 郭大海, 刘广忱, 张进, 等. 飞轮储能阵列系统协调控制方法综述[J]. 内蒙古电力技术, 2024, 42(4): 56-65. DOI: 10.19929/j.cnki.nmgdljs.2024.0054. |
| GUO D H, LIU G C, ZHANG J, et al. Overview of coordinated control methods for flywheel energy storage array system[J]. Inner Mongolia Electric Power, 2024, 42(4): 56-65. DOI: 10. 19929/j.cnki.nmgdljs.2024.0054. | |
| 9 | JI W M, HONG F, ZHAO Y Z, et al. Applications of flywheel energy storage system on load frequency regulation combined with various power generations: A review[J]. Renewable Energy, 2024, 223: 119975. DOI: 10.1016/j.renene.2024.119975. |
| 10 | CHOUDHURY S. Flywheel energy storage systems: A critical review on technologies, applications, and future prospects[J]. International Transactions on Electrical Energy Systems, 2021, 31(9): e13024. DOI: 10.1002/2050-7038.13024. |
| 11 | 金都, 刘广忱, 孙博文, 等. 计及风电场的飞轮储能一次调频控制策略[J]. 储能科学与技术, 2024, 13(6): 1911-1920. DOI: 10.19799/j.cnki.2095-4239.2024.0039. |
| JIN D, LIU G C, SUN B W, et al. Primary frequency modulation control strategy for flywheel energy storage counting and wind farms[J]. Energy Storage Science and Technology, 2024, 13(6): 1911-1920. DOI: 10.19799/j.cnki.2095-4239.2024.0039. | |
| 12 | 曹一凡.飞轮储能阵列并网运行与稳定性分析研究[D].北京: 清华大学, 2024. |
| CAO Y F. Research on flywheel energy storage array grid-connected operation and stability analysis[D]. Beijing: Tsinghua University, 2024. | |
| 13 | MARUPI M, BATOOL M, ALIZADEH M, et al. Transient stability improvement of large-scale photovoltaic grid using a flywheel as a synchronous machine[J]. Energies, 2023, 16(2): 689. DOI: 10. 3390/en16020689. |
| 14 | 郭文勇, 闵瑞祺, 桑文举, 等. 飞轮储能调频调相系统: CN116316741A[P]. 2023-06-23. |
| GUO W Y, MIN R Q, SANG W J, et al. Flywheel energy storage frequency modulation and phase modulation system: CN116316 741A[P]. 2023-06-23. | |
| 15 | 包广清, 郭风堂. 基于电磁耦合器调速的同步发电机控制研究[J]. 微特电机, 2017, 45(5): 75-79. DOI: 10.3969/j.issn.1004-7018.2017. 05.020. |
| BAO G Q, GUO F T. Study of maximum power point tracking method of wind turbine generator based on an electromagnetic coupler[J]. Small & Special Electrical Machines, 2017, 45(5): 75-79. DOI: 10.3969/j.issn.1004-7018.2017.05.020. | |
| 16 | YOU R, BARAHONA B, CHAI J Y, et al. Frequency support capability of variable speed wind turbine based on electromagnetic coupler[J]. Renewable Energy, 2015, 74: 681-688. DOI: 10.1016/j.renene.2014.08.072. |
| 17 | 李杰. 电磁耦合调速式风力发电机组模拟实验系统的研究[D]. 北京: 清华大学, 2012. |
| LI J. Research on the Simulation Experiment System of Wind Generating Set Based on Electromagnetic Coupler[D]. Beijing: Tsinghua University, 2012. | |
| 18 | 余文浩, 齐立哲, 梁瀚文, 等. 基于深度强化学习的分层自适应PID控制算法[J]. 计算机系统应用, 2024, 33(9): 245-252. DOI: 10. 15888/j.cnki.csa.009598. |
| YU W H, QI L Z, LIANG H W, et al. Hierarchical adaptive PID control algorithm based on deep reinforcement learning[J]. Computer Systems and Applications, 2024, 33(9): 245-252. DOI: 10.15888/j.cnki.csa.009598. | |
| 19 | 张苹. 变参数PID控制在大功率空气加热系统中的应用研究[D]. 绵阳: 西南科技大学, 2021. DOI: 10.27415/d.cnki.gxngc. 2021. 000888. |
| ZHANG P. Application of variable-parameter PID control in high-power air heating system[D]. Mianyang: Southwest University of Science and Technology, 2021. DOI: 10.27415/d.cnki.gxngc. 2021.000888. | |
| 20 | 姚崇, 董璕, 李瑞, 等. 基于强化学习的柴油机调速算法研究[J]. 内燃机工程, 2024, 45(4): 71-80. DOI: 10.13949/j.cnki.nrjgc.2024. 04.009. |
| YAO C, DONG X, LI R, et al. Research on diesel engine speed regulation algorithm based on reinforcement learning[J]. Chinese Internal Combustion Engine Engineering, 2024, 45(4): 71-80. DOI: 10.13949/j.cnki.nrjgc.2024.04.009. | |
| 21 | 周志勇, 莫非, 赵凯, 等. 基于PPO的自适应PID控制算法研究[J]. 系统仿真学报, 2024, 36(6): 1425-1432. DOI: 10.16182/j.issn 1004731x.joss.23-0137. |
| ZHOU Z Y, MO F, ZHAO K, et al. Adaptive PID control algorithm based on PPO[J]. Journal of System Simulation, 2024, 36(6): 1425-1432. DOI: 10.16182/j.issn1004731x.joss.23-0137. | |
| 22 | 李永东, 郑泽东. 交流电机数字控制系统[M]. 3版. 北京: 机械工业出版社, 2017. |
| LI Y D, ZHENG Z D. Digital control system of AC motor[M]. 3rd ed. Beijing: China Machine Press, 2017. | |
| 23 | 徐慧. 电力系统中储能装置辅助PSS优化控制策略[D]. 成都: 西南交通大学, 2019. DOI: 10.27414/d.cnki.gxnju.2019.002476. |
| XU H. Optimal control strategy of PSS aided by energy storage device in power system[D]. Chengdu: Southwest Jiaotong University, 2019. DOI: 10.27414/d.cnki.gxnju.2019.002476. | |
| 24 | ZHAO P, YAO W, WANG S R, et al. Decentralized nonlinear synergetic power system stabilizers design for power system stability enhancement[J]. International Transactions on Electrical Energy Systems, 2014, 24(9): 1356-1368. DOI: 10.1002/etep. 1788. |
| 25 | 孙桥枫. 基于强化学习的电力系统稳定器优化设计研究[D]. 成都: 电子科技大学, 2021. DOI: 10.27005/d.cnki.gdzku.2021.001387. |
| SUN Q F. Research on optimal design of power system stabilizer based on reinforcement learning[D]. Chengdu: University of Electronic Science and Technology of China, 2021. DOI: 10. 27005/d.cnki.gdzku.2021.001387. |
| [1] | 王艺斐, 徐帆, 王亮, 戴兴建, 徐玉杰, 陈海生. 飞轮储能系统电机定子散热设计研究[J]. 储能科学与技术, 2025, 14(5): 1946-1953. |
| [2] | 许庆祥, 滕伟, 秦润, 宋顺一, 柳亦兵, 梁双印. 电网调频飞轮储能系统并网能量管理与控制策略[J]. 储能科学与技术, 2025, 14(5): 2013-2022. |
| [3] | 武小兰, 马彭杰, 白志峰, 刘成龙, 郭桂芳, 张锦华. 一种锂离子电池组智能PID双层主动均衡控制方法[J]. 储能科学与技术, 2025, 14(3): 1150-1159. |
| [4] | 董文琦, 张东晖, 曹一凡, 宁照轩, 姜新建, 李明, 史学伟. 新型惯量飞轮与高速飞轮参与电网惯性响应与一次调频的控制策略[J]. 储能科学与技术, 2025, 14(3): 1224-1233. |
| [5] | 李玉光, 刘翔, 梁艳召, 刘双振. 飞轮储能装置在轨道交通中的应用研究[J]. 储能科学与技术, 2024, 13(8): 2679-2686. |
| [6] | 周茜茜, 黄勇, 崔可, 孙大南. 飞轮储能装置电机温度场仿真技术研究及试验验证[J]. 储能科学与技术, 2024, 13(8): 2589-2596. |
| [7] | 金都, 刘广忱, 孙博文, 黄天园, 张建伟, 田桂珍, 荆丽丽. 计及风电场的飞轮储能一次调频控制策略[J]. 储能科学与技术, 2024, 13(6): 1911-1920. |
| [8] | 马海凤, 李文博, 蔡宗慧, 刘琳, 于彤. 飞轮储能系统的计算机处理技术研究[J]. 储能科学与技术, 2024, 13(6): 1983-1985. |
| [9] | 李红, 吕江毅, 宋建桐, 闫栋. 车用机电复合储能系统的能量特性分析[J]. 储能科学与技术, 2024, 13(3): 906-913. |
| [10] | 孙冉, 王建波, 马彦钊, 张小科, 胡怀中. 基于强化学习的新能源场站储能一次调频自适应控制策略[J]. 储能科学与技术, 2024, 13(3): 858-869. |
| [11] | 徐帆, 戴兴建, 王又珑, 胡东旭, 张华良, 陈海生. 飞轮储能用永磁电机研究进展[J]. 储能科学与技术, 2024, 13(10): 3423-3441. |
| [12] | 滕国营, 王新改, 孟海军, 丁飞. 高功率储能器件的研究进展[J]. 储能科学与技术, 2024, 13(10): 3442-3452. |
| [13] | 张志国, 王刚, 杨晶, 王书平, 刘东, 饶武峰. MW级飞轮阵列在新能源场站一次调频中的应用[J]. 储能科学与技术, 2024, 13(10): 3569-3578. |
| [14] | 左兴龙, 柳亦兵, 秦润, 曲文浩, 滕伟. 飞轮储能虚拟同步机动态特性及对电力系统频率的改善分析[J]. 储能科学与技术, 2023, 12(6): 1920-1927. |
| [15] | 李斌, 叶季蕾, 张宇, 时珊珊, 王皓靖, 刘丽丽, 李明哲. 含分布式新能源和机电混合储能接入的微网协调控制策略[J]. 储能科学与技术, 2023, 12(5): 1510-1515. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
